如何在Windows中安装Spark3.5并运行
首先,我们理一下 Spark 3.5 的依赖:
- JDK
- Spark3.x支持Java 8和Java 11,首选Java 11
- Apache Spark
- Hadoop
- 本地运行Spark需要依赖一些Hadoop的内容
下面我们逐个安装并配置。
第一步:安装并配置Java
- 下载JDK11 Download Link
- 安装
- 配置环境变量
- 新建环境变量:JAVA_HOME,设置值为JDK11的安装目录
-默认为: C:\Program Files\OpenLogic\jdk-11.0.23.9-hotspot\
- 新建环境变量:JAVA_HOME,设置值为JDK11的安装目录
- 配置默认Java options(可选)
- 环境变量名称:_JAVA_OPTIONS
- 值 -Xms1024M,这个参数设置 JVM 启动时分配的堆内存的初始大小。堆内存是用来存放 Java 对象的。示例中为1G。
- 值 -Xmx4096M,这个参数设置 JVM 能够分配的最大堆内存大小。堆内存可以在程序运行期间动态扩展,但不会超过这个值。示例中为4G
- 验证
- 在命令行运行: java –version
第二步,安装并配置Apache Spark
- 下载:spark-3.5.1-bin-hadoop3.tgz
- 解压到安装目录,可自己定义,例如:D:\Spark\spark-3.5.1-bin-hadoop3
- 配置环境变量
- 将spark bin目录添加到PATH环境变量
- D:\Spark\spark-3.5.1-bin-hadoop3\bin
- 将spark安装目录设置为环境变量:SPARK_HOME
- D:\Spark\spark-3.5.1-bin-hadoop3
- 将spark bin目录添加到PATH环境变量
- 验证:打开命令行输入以下命令
- spark-submit –version
第三步,安装并配置Hadoop依赖
- 下载repo(Download as Zip):https://github.com/steveloughran/winutils
- 解压,并将 hadoop-3.0.0 目录复制到任意目录,例如:D:\Spark\hadoop-3.0.0
- 配置环境变量
- 新建环境变量 HADOOP_HOME 并设置为下面的值
- D:\Spark\hadoop-3.0.0
- 新建环境变量 HADOOP_HOME 并设置为下面的值
- 验证
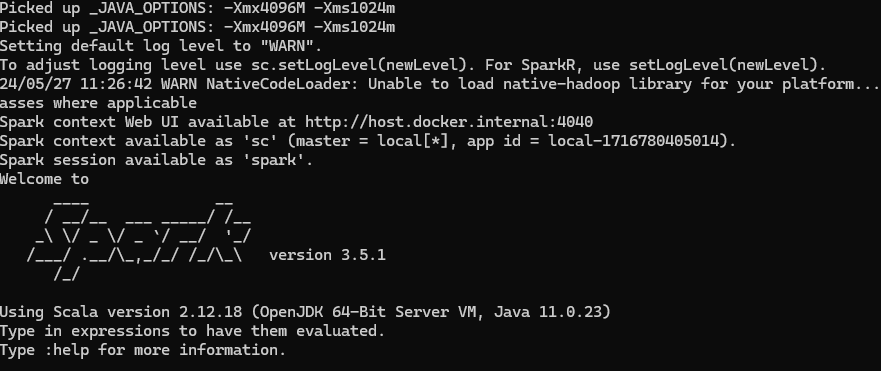
- 在命令行运行: spark-shell
- 正常情况下会看到如下页面
第四步,安装pyspark
- 在python环境中安装pyspark,如果已经安装了旧版本的pyspark,请先卸载后再安装。
1
pip install pyspark==3.5.1 - 配置环境变量
- 如果你安装pyspark的环境不是windows默认的python环境(比如你在anaconda管理的虚拟环境中安装了pyspark),那么需要配置环境变量:PYSPARK_PYTHON
- 例如:D:\anaconda3\python.exe
- 如果你安装pyspark的环境不是windows默认的python环境(比如你在anaconda管理的虚拟环境中安装了pyspark),那么需要配置环境变量:PYSPARK_PYTHON
- 验证:用python运行如下脚本
1
2
3
4
5
6
7
8
9
10
11
12
13from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("Test PySpark").getOrCreate()
# Sample data
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
# Create DataFrame
df = spark.createDataFrame(data, ["Name", "Age"])
# Show DataFrame
df.show() - 注意:如果遇到缺少包的报错,直接在python里面安装对应的包即可。
如何在Windows中安装Spark3.5并运行
http://yoursite.com/posts/49568/