详解 Spark 中的 Bucketing
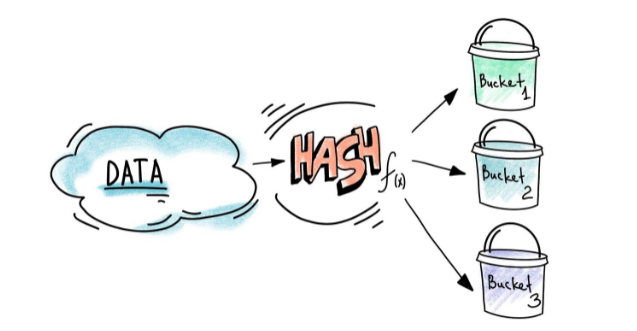
什么是 Bucketing
Bucketing 就是利用 buckets(按列进行分桶)来决定数据分区(partition)的一种优化技术,它可以帮助在计算中避免数据交换(avoid data shuffle)。并行计算的时候shuffle常常会耗费非常多的时间和资源.
Bucketing 的基本原理比较好理解,它会根据你指定的列(可以是一个也可以是多个)计算哈希值,然后具有相同哈希值的数据将会被分到相同的分区。
Bucket和Partition的区别
Bucket的最终目的也是实现分区,但是和Partition的原理不同,当我们根据指定列进行Partition的时候,Spark会根据列的名字对数据进行分区(如果没有指定列名则会根据一个随机信息对数据进行分区)。Bucketing的最大不同在于它使用了指定列的哈希值,这样可以保证具有相同列值的数据被分到相同的分区。
怎么用 Bucket
按Bucket保存
目前在使用 bucketBy 的时候,必须和 sortBy,saveAsTable 一起使用,如下。这个操作其实是将数据保存到了文件中(如果不指定path,也会保存到一个临时目录中)。
1 | |
数据分桶保存之后,我们才能使用它。
直接从table读取
在一个SparkSession内,保存之后你可以通过如下命令通过表名获取其对应的DataFrame.
1 | |
其中spark是一个SparkSession对象。获取之后就可以使用DataFrame或者在SQL中使用表。
从已经保存的Parquet文件读取
如果你要使用历史保存的数据,那么就不能用上述方法了,也不能像读取常规文件一样使用 spark.read.parquet() ,这种方式读进来的数据是不带bucket信息的。正确的方法是利用CREATE TABLE 语句,详情可用参考 https://docs.databricks.com/spark/latest/spark-sql/language-manual/create-table.html
1 | |
示例如下:
1 | |
用Buckets的好处
在我们join两个表的时候,如果两个表最好按照相同的列划分成相同的buckets,就可以完全避免shuffle。根据前面所述的hash值计算方法,两个表具有相同列值的数据会存放在相同的机器上,这样在进行join操作时就不需要再去和其他机器通讯,直接在本地完成计算即可。假设你有左右两个表,各有两个分区,那么join的时候实际计算就是下图的样子,两个机器进行计算,并且计算后分区还是2.
graph LR;
p1[Left Partiton 1]
p2[Left Partiton 2]
rp1[Right Partiton 1]
rp2[Right Partiton 2]
w1[Executor 1]
w2[Executor 2]
p1-->w1
p2-->w2
rp1-->w1
rp2-->w2
而当需要shuffle的时候,会是这样的,
graph LR;
p1[Left Partiton 1]
p2[Left Partiton 2]
rp1[Right Partiton 1]
rp2[Right Partiton 2]
w1[Executor 1]
w2[Executor 2]
w3[Executor 3]
p1-->w1
p1-->w2
p1-->w3
p2-->w1
p2-->w2
p2-->w3
rp1-->w1
rp1-->w2
rp1-->w3
rp2-->w1
rp2-->w2
rp2-->w3
细心的你可能发现了,上面两个分区对应两个Executor,下面shuffle之后对应的怎么成了三个Executor了?没错,当数据进行shuffle之后,分区数就不再保持和输入的数据相同了,实际上也没有必要保持相同。
本地测试
我们考虑的是大数据表的连接,本地测试的时候一般使用小的表,所以逆序需要将小表自动广播的配置关掉。如果开启小表广播,那么两个小表的join之后分区数是不会变的,例如:
| 左表分区数 | 右表分区数数 | Join之后的分区数 |
|---|---|---|
| 3 | 3 | 3 |
关闭配置的命令如下:
1 | |
正常情况下join之后分区数会发生变化:
| 左表分区数 | 右表分区数数 | Join之后的分区数 |
|---|---|---|
| 3 | 3 | 200 |
这个200其实就是 “spark.sql.shuffle.partitions” 配置的值,默认就是200. 所以如果在Join过程中出现了shuffle,join之后的分区一定会变,并且变成spark.sql.shuffle.partitions的值。通常你需要根据自己的集群资源修改这个值,从而优化并行度,但是shuffle是不可避免的。
左右两个表Bucket数目不一致时
实际测试结果如下:
| 左表Bucket数 | 右表Bucekt数 | Join之后的分区数 |
|---|---|---|
| 8 | 4 | 8 |
| 4 | 4 | 4 |
Spark依然会利用一些Bucekt的信息,但具体怎么执行目前还不太清楚,还是保持一致的好。
另外,如果你spark job的可用计算核心数小于Bucket值,那么从文件中读取之后Bucekt值会变,就是说bucket的数目不会超过你能使用的最大计算核数。
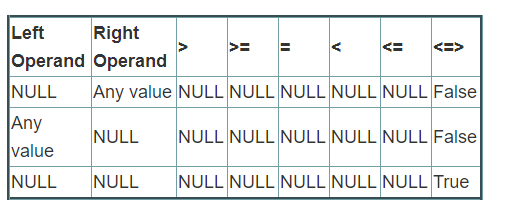
不要使用的 <=> 符号!!!
在处理null值的时候,我们可能会用到一些特殊的函数或者符号,如下表所示。但是在使用bucket的时候这里有个坑,一定要躲过。join的时候千万不要使用 <=> 符号,使用之后spark就会忽略bucket信息,继续shuffle数据,原因可能和hash计算有关。