机器学习为什么强大?
机器学习的本质就是计算机从数据中学习知识,这一过程与人学习的过程十分相似,也正因此机器学习可以有效地帮助人们解决问题。

人的知识是怎么来呢?埃斯库罗斯说:“ 记忆是一切智慧之母”(《被缚的普罗米修斯》)。的确,没有记忆就没有智慧,我们所拥有的知识,大部分都是靠记忆得来的。所以学习的过程注定艰苦,不管你有多少记忆方法和记忆捷径,都无法突破人脑本身的限制,总是要一点一滴去记忆。我的母校中国科学技术大学的少年班是培养少年天才最知名的地方,据我了解少年班录取过最小的学员有11岁,这差不多是最低年龄的极限了。无论多么天才,七八年的知识积累是无法跳过去的,没有绝对的捷径。
埃斯库罗斯名言的英文版是:Memory is the mother of all wisdom。计算机中的内存就叫 Memory,内存用来存储数据,在计算机的世界里这句名言应该这么说:“ 数据是一切智慧之母”。计算机比人有一个巨大的优势,它的“记忆”(也就是收集数据的过程)需要的时间很短,远远比人需要的时间短。从这个角度看,假如计算机复刻了人的学习过程,那么机器学习比人更强大就是一件顺理成章的事情了。实际上,在很多问题上已经是这样了。
在机器学习领域,数据常常比算法要重要的多,数据决定了机器学习能力的上限。数据/记忆是知识的根本,但显然他们还不等于知识。首先我们需要对数据“解码”,否则他们只是一堆“01”串而已;其次要从中识别出对我们有用的信息。
人是如何从记忆的数据中获取到知识的呢?用”识字“这个非常简单的例子来说明一下。所有的汉字大约有10万个,常用的汉字约有3500个,在我们还没有学会认字之前,即使你能记住这些字长什么样,它们在你眼里也都只是“字”。根据信息熵的定义(https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%86%B5),如果给你一个字,在你眼里没有区别,那么它只有一种可能取值:“字”,并且概率是1.0,我们可以计算这一信息量。
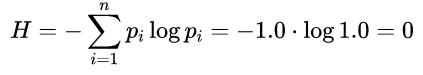
所以,光记住没有用,如果不能辨识每个字的意思,你掌握的信息量还是0。只考虑常用汉字,假设3500个汉字你已经全部掌握,再假设这些字出现的概率都是相同的,于是你掌握的信息量如下:
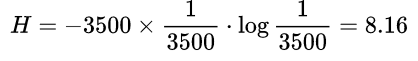
人之初,善恶无。天地混沌一片,我们一无所知。“天和地还没有分开,宇宙混沌一片。有个叫盘古的巨人,在这混沌之中,一直睡了一万八千年。 有一天,盘古突然醒了。他见周围一片漆黑,就抡起大斧头,朝眼前的黑暗猛劈过去。只听一声巨响,混沌一片的东西渐渐分开了。轻而清的东西,缓缓上升,变成了天;重而浊的东西,慢慢下降,变成了地。” 盘古开天辟地,是人类的开始;我们识文断字,明辨是非,是智慧的开始。
机器学习中最重要的一类问题就是分类,分类让计算机具有了智慧。分类的概念很好理解,是非、善恶、美丑这都是分类,分类的数学模型也好理解,如下图。
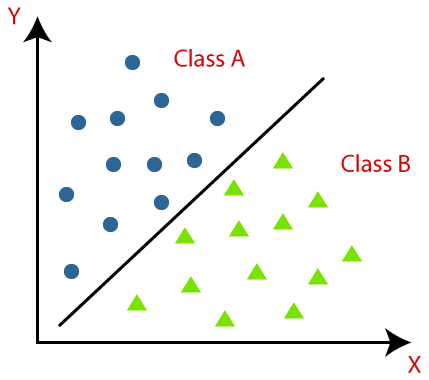
机器需要学习的就是一条”分割线“,能将平面上属于不同类别的点区分开。
我一直觉得,就算有些理论比较难,但机器学习的概念和其要解决的问题都很好理解,如果更多人能了解一些相关知识,AI对大众就不再是个黑盒子,那样会减少很多不必要的社会问题。
分类问题的应用举例
- 垃圾邮件识别
- 判断是否为垃圾邮件,二分类
- 音乐、商品、书籍等各种推荐
- 判断你喜欢还是不喜欢,二分类
- 广告点击率估计
- 判断你点击还是不点击,二分类
- 小爱、Siri等语音助手
- 识别你的意图,多分类
- 人类识别
- 识别是否为人脸,二分类
总之,计算机从数据中学习知识的过程与人学习的过程有很多相似之处,并且它还具有以下优势:机器学习获取数据的速度和数量要远超过人类,即机器学习可以被大数据赋能;机器学习可以做到一次学习,多处复制。所以,机器学习的名字并不是白叫的。
